Privacy Canada is community-supported. We may earn a commission when make a purchase through one of our links. Learn more.
Pseudo-Random Number Generation

Computers, by themselves, are deterministic in nature – that is they work with inputs and ouputs, and based on certain inputs you will always receive certain outputs in return. It’s operations are predictable, and more importantly, repeatable.
These days computers have external resources they can use to obtain “truly random” numbers – often from external sources such as background noise, the current nanosecond of time, or other external events not related to the computer itself. However, what if we wanted to generate a bunch of random numbers in a repeatable fashion? We use something called a seed.
The seed is often an initial truly random number, or in some applications just some chosen number. The seed can then be used to generate pseudo-random numbers, all determined by the initial seed value.
An excellent example of this is the middle-square method of generating pseudo-random numbers. In the middle-square method, you take the seed, multiply it by itself (the square) and then take the “middle” of the resulting number – That is, the numbers enclosed within the result’s first and last digit.
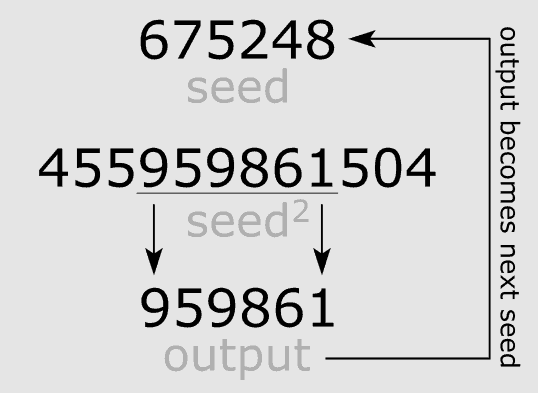
As an example, let’s start off with a seed value of 124. We then take this seed value, multiply it by itself, and then take middle numbers of the result.
The result of this first seed-based pseudo-random generated number is then used as the input to generate the next number, as follows:
This process could be used for as many numbers as you would like – assuming the initial seed was big enough. This brings us to the one flaw with pseudo-random number generation: they repeat. Depending on the size of the initial seed, sooner or later regardless of the method used, the function will eventually output a seed value it has already used, and from that point on it starts repeating. Now, for three digit numbers, this would be after generating thousands of numbers, but for very large numbers this repeat point would take a very long time to reach.